Share this
by Jan Hendrik Fleury on Aug 24, 2021 10:51:04 AM

For many years, the architectures of a Data Warehouse and a Data Lake have been viewed as separate systems applicable to specific data types and user skill sets. That’s history. Recent innovations allow us to create a comprehensive platform that gives us the best of both worlds.
We want end-to-end data management and processing.
We have been creating end-to-end solutions covering data management and processing stages, from data collection to data analysis and machine learning. The result is a data platform that can store vast amounts of data in varying formats without compromising on latency. At the same time, this platform can satisfy the needs of all users throughout the data lifecycle.
One of the aspects I love about our work is that there is no one-size-fits-all approach to building an end-to-end data solution. Emerging concepts include data lakehouses, data meshes, and data vaults that seek to meet specific technical and organizational needs. All of them work naturally within a Google Cloud environment. It really does. We have several clients who are enjoying the benefits of the converging technologies.
Data Mesh, Data Lake, Data Vault
Data mesh facilitates a decentralized approach to data ownership, allowing individual lines of business to publish and subscribe to data in a standardized manner, instead of forcing data access and stewardship through a single, centralized team.
On the other hand, a Data Lakehouse brings raw and processed data closer together, enabling a more streamlined and centralized repository of data needed throughout the organization. Processing can be done in transit via ELT in BigQuery, reducing the need to copy datasets across systems. This is making data exploration and governance easier.
The Data lakehouse works to store the data in a single source of truth, making minimal copies of the data. This architecture offers low-cost storage in an open format accessible by various processing engines like Spark while also providing powerful management and optimization features. Consistent security and governance are key to any lakehouse.
Finally, a data vault is designed to separate data-driven and model-driven activities. Data integrated into the raw vault enables parallel loading to facilitate the scaling of large implementations.
In Google Cloud, there is no need to keep them separate. In fact, with interoperability among our portfolio of data analytics products, you can easily provide access to data residing in different places, effectively bringing your data lake and data warehouse together on a single platform.
Under the hood
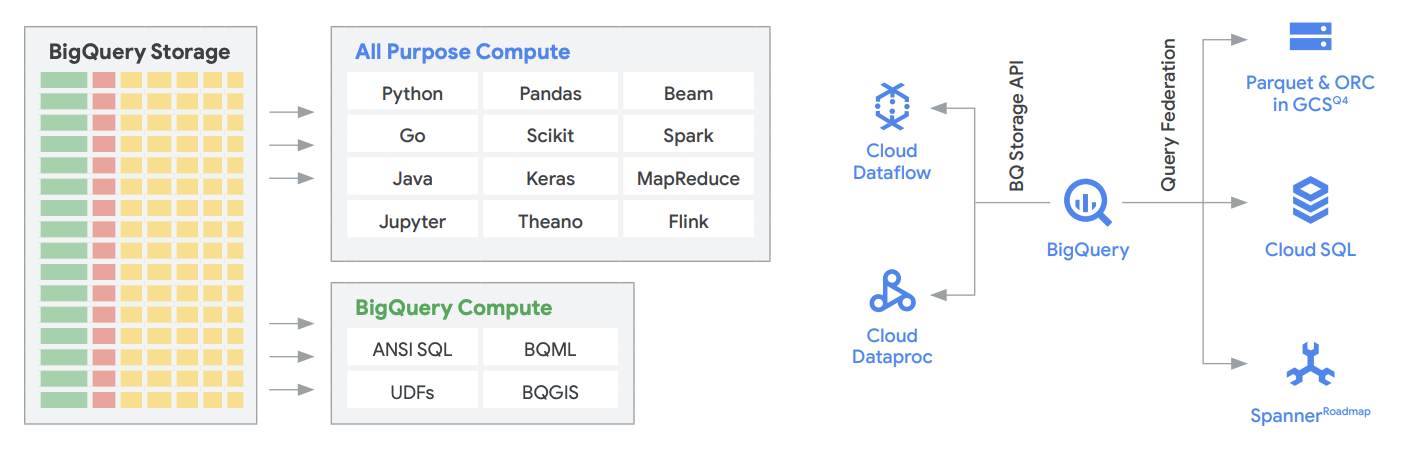
Let's look at some of the technological innovations that make this reality. BigQuery’s storage API allows treating a data warehouse as a data lake, letting you access the data residing in BigQuery.
For example, you can use Spark to access data residing in the data warehouse without it affecting the performance of any other jobs accessing it. This is all made possible by the underlying architecture, which separates compute and storage. Likewise, Dataplex, Google’s intelligent data fabric service, provides data governance and security capabilities across various lakehouse storage tiers built on GCS and BigQuery.
Point solutions versus a truly unified analytics platform
What sets Google Cloud’s data analytics platform apart is that it is open, intelligent, flexible, and tightly integrated. Many technologies in the market provide tactical solutions that may feel comfortable and familiar.
However, this can be a short-term approach that simply lifts and shifts a siloed solution into the cloud. In contrast, an analytics data platform built on Google Cloud offers modern data warehousing and data lake capabilities that are closely integrated with their AI Platform. It also provides built-in streaming, ML, and geospatial capabilities and an in-memory solution for BI use cases.
Let’s talk about shaping your analytics capabilities over a coffee!


